Link: https://patents.google.com/patent/US20120191694A1/en
In 2012, Apple filed a patent titled “Generation of Topic-Based Language Models for an App Search Engine” (US20120191694A1). The filing outlines a system that enables function-based search for mobile applications, going beyond traditional keyword or title-based queries.
This post explores the technical foundation of the patent, how topic models are constructed, and the role of post-processing in refining search relevance.
The Problem: Function Over Title
Traditional app stores often rely on exact-match queries—limiting results to app titles or developer names. Apple’s patent addresses this by introducing topic-based language models that let users search by what an app does, not just what it’s called:
“An implicit search engine enables searching for mobile applications (also referred to as ‘apps’), based on their function rather than their name.” (Section 0008)
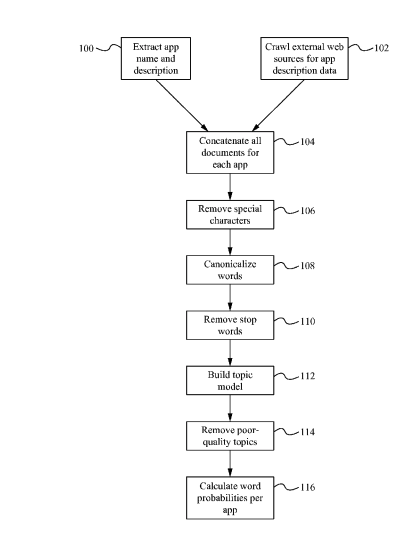
Step-by-Step: How the Topic Model is Built
The process of constructing a topic-based language model follows these major stages:
1. Data Collection and Normalization
- Input Sources: App names and descriptions from app stores, plus crawled web sources like app review sites.
- Concatenation: All description data is aggregated for each app.
“External web sources are crawled for app description data… The information for each app gathered… is concatenated together.” (Section 0011)
2. Text Cleaning and Normalization
- Remove Special Characters: Strip HTML, non-standard text (Step 106).
- Canonicalize Words: Apply stemming or lemmatization to normalize words like “text,” “texting,” and “texts” into a base form.
- Remove Stop Words: Words like “a,” “the,” “and” are discarded to reduce noise.
3. Topic Modeling
Apple uses a probabilistic topic modeling algorithm such as Latent Dirichlet Allocation (LDA) to group co-occurring words:
“One example of a grouping algorithm (also referred to as topic modeling) is Latent Dirichlet Allocation…” (Section 0011)
Each app is represented as a distribution over multiple topics, and each topic is a distribution over words. For example, a “restaurant finder” topic might include words like “food,” “nearby,” “eat,” and “review.”
Word Probability Calculation
Once topics are assigned, the system calculates the probability of each word appearing in a given app’s context:
“This value indicates the strength of association between a word and an app… based on the probability that a topic contains a word and the probability that a document contains a topic.” (Section 0011)
These word probabilities are used to build the language model for each app.
Post-Processing for Relevance
To refine accuracy and ensure real-world relevance, Apple’s system incorporates query log data:
“Relevant query terms are added to the app’s language model… if users search for the word ‘Facebook’ and overwhelmingly download the Facebook app…” (Section 0012)
This step includes:
- Filtering out irrelevant words not present in the app’s actual description.
- Adding user-generated terms from search logs with strong download correlations.
- Manual review of topics for quality assurance (Section 0011, 0012).
Implementation Architecture
Apple provides a hardware-agnostic outline for deploying this system. The topic model engine can run on various platforms, from cloud-based servers to embedded systems:
“Examples of suitable computing devices include… smartphone (e.g., an iPhone), tablet (e.g., an iPad), cloud-coupled device…” (Section 0015)
The model generation application can be deployed via:
- Software (stored in memory and executed by CPU)
- Hardware logic (e.g., gates in FPGAs or ASICs)
- Hybrid systems (Section 0013)
Use Case: App Search by Function
Imagine searching “budget tracker” in the App Store. Traditional search engines may not surface lesser-known apps if the title doesn’t include “budget” or “tracker.” With Apple’s topic-based system, the engine matches your query to apps whose topic vectors closely align with budgeting functions—even if the app title is something creative like “MoneyTree.”
Patent Claims of Interest
A few key claims from the patent:
- Claim 7: “…processing the description… comprises building a topic model.”
- Claim 13: “…generating the topic-based language model comprises calculating word probabilities.”
- Claim 17: “…adding the relevant query terms to the topic-based language model.”
Final Thoughts
Apple’s patent is a forward-thinking solution to the shortcomings of conventional app search. By leveraging topic modeling, NLP preprocessing, and user behavior logs, this system dramatically improves app discoverability—especially for function-driven queries.
For developers, marketers, and machine learning engineers, it’s a valuable case study in applying unsupervised learning to real-world discovery engines.
Bir yanıt yazın